Django migrations without downtimes
Jul 14, 2015 · 12 minute readMost web applications use a relational database. The database schema needs to be changed over time as features are added, changed or removed. These database migrations need to be designed and integrated in your deployment process. On the one hand, scheduled downtimes can be expensive for the business and are painful to organize for larger sites or organizations. On the other hand, applying migrations on a live system can bring down your web-server in counter-intuitive ways. I’ll talk about common schema change scenarios and how those can be safely carried out on a live system with a Postgres database. We’ll look at locking and timing issues, multi-phase deployments and migration system peculiarities.
Introduction
Database migrations are the major obstacles in adopting continuous deployment for a web application. While tool support has improved considerably in the last years, actually deploying these database changes continues to be a stressful chore. For the uninitiated, there are two ways to approach database migrations.
With the optimistic approach, one just applies database migrations on a live system and hopes for the best. This goes well some of the times, other times there are outages and the migration must be aborted. Optimistic migrations are always thrilling, but might become overwhelming if unscheduled downtimes are unacceptable in your specific use case.
If you burnt your fingers too many times you might switch to the pessimistic approach: You schedule a downtime for each database migration. Nothing will unexpectedly lock up, instead you’ll just be down a lot. Because your customers wouldn’t like this, you’ll bundle up migrations and delay most deployments until the next maintenance window opens.
These are of course exaggerations, but are supposed to illustrate that neither approach is particularly attractive. Both turn database migrations into a burden that developers will try to avoid to carry. In the worst case, the schema won’t be changed if it can be avoided leading to subpar data modeling.
Understanding the kind of issues that arise during online migrations should help you avoid both unexpected outages and unnecessary downtimes.
Scenarios
Let’s look at migrations scenarios, starting with the most common cases. Throughout this article I assume you use Django 1.7 or above, Django migrations as the DB migration tool, and Postgres as your SQL database.
Add a table
Adding a new table is simple - as nobody is accessing this table when your migration is run, you just need to make sure to run the migration before the code accessing the table is deployed.
Here’s an illustration of how this looks on a common small-scale configuration with three application servers and one database server:
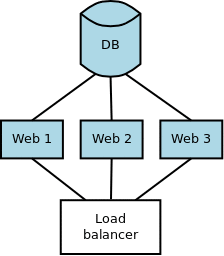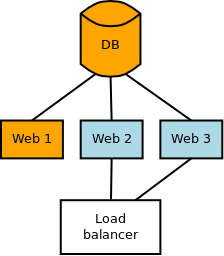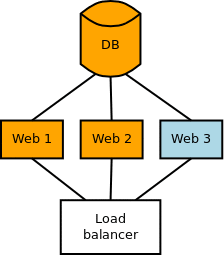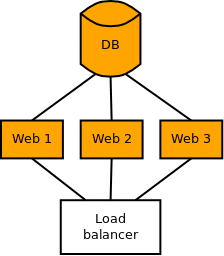
If you apply migrations from your application servers, it is quite easy automating this kind of migration as part of the deployment process:
- Deactivate one server in the load balancer configuration (or rely on auto-failover)
- Deploy new code to that server
- Run
django-admin migrate - Reactivate the server in the load balancer configuration
As Django migrations are idempotent, it’s safe to execute the migration command from each server as long as you don’t call those commands in parallel. However, not all migrations can be applied before the code goes live as we’ll see when we get to column removal.
Add a column
Adding a column to an existing table is probably the most common database operation. How hard it is to add a column to an existing table depends on many factors:
Locks
When adding a column to a table you implicitly grab an exclusive lock on the
table. If any reads or writes are performed on the table while you
try to apply the migration, the ALTER TABLE statement will be blocked. All
active operations on the table need to complete before the migration can
proceed. As soon as the migration is started, subsequent reads and writes on
the table are blocked until the migration is complete.
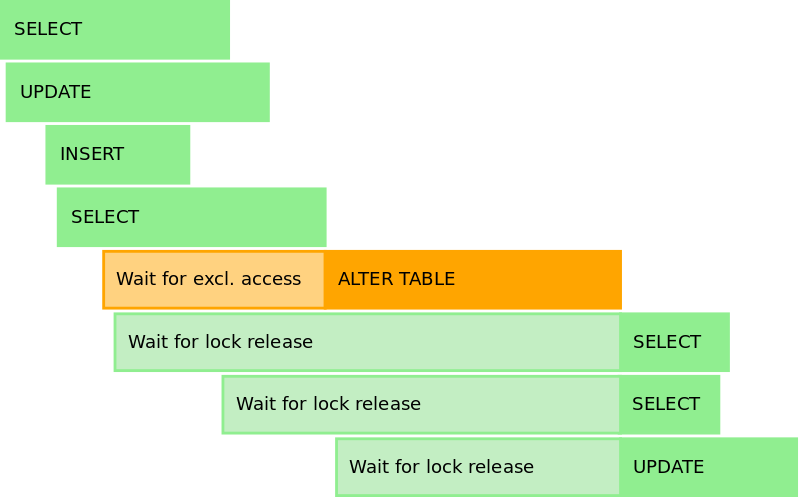
In Postgres blocked queries queue up in a simple FIFO waiting list. There is no reader-writer preference so even plain reads queue up behind your blocked alter table statement.
That means that you not only need to care about the processing time incurred by the alter table statement, but also about long-running queries that might be running when you try to apply your migration. Thus, if you have any asynchronous services that use slow queries, you might want to shut those down before running your migrations.
Transactions
Postgres supports transactional DDL. The current versions of Django put the transactional scope on the migration level. In other words, one migration is executed in one transaction. Database locks are held until the end of the database transaction. If you modify multiple tables at the same time, you might want to split the associated migrations in small chunks so that locks aren’t held for longer than necessary and the risk of deadlocks is reduced.
Table rewrites
The figure above illustrates the importance of the DDL statement finishing in a very short time, so that all blocked queries can resume before the associated requests time out.
When adding columns with default values, Postgres will modify all existing rows of the table which can be a very expensive operation if the table contains a lot of data. Essentially, Postgres will copy all existing rows (MVCC) and add the new column’s default value to each row.
Adding nullable columns without defaults doesn’t require full table rewrites as stated in the Postgres manual:
When a column is added with ADD COLUMN, all existing rows in the table are initialized with the column’s default value (NULL if no DEFAULT clause is specified). If there is no DEFAULT clause, this is merely a metadata change and does not require any immediate update of the table’s data; the added NULL values are supplied on readout, instead.
NULL or NOT NULL
From an operations perspective you could just declare all your fields as nullable and circumvent a lot of problems when applying migrations. However, there are a lot of downsides when working with fields that contain NULL values.
As long as you deal with individual objects, null values work well. But you got to be careful when using nullable fields in query filters:
if not user.blocked:
# Works with `False` and `NULL`
User.objects.filter(blocked=False) # XXX
User.objects.filter(~Q(blocked=True))
User.objects.exclude(blocked=True)
Default values
Django is pretty opinionated in what it pushes down to the database. There is one thing in particular that you’ll have to consider when trying to perform migration without downtimes: Default values.
Django is pretty clear about not keeping defaults in the database. What Django does push down though, are not null constraints (which is a good thing). If you perform migrations during downtimes this doesn’t matter. However, if you add a new column with a not-null constraint and the default is not stored in the database, any insert operation executed from the currently running version will fail with a constraint violation because it doesn’t know about this new column.
You can’t easily tell Django not to drop the constraint in the automatically created operation. However, you can override the original migration by using RunSQL while specifying the original state operation.
RunSQL(
'ALTER TABLE users ADD COLUMN blocked BOOLEAN NOT NULL DEFAULT false',
'ALTER TABLE users DROP COLUMN blocked',
state_operations=[
migrations.AddField(
model_name='users',
name='blocked',
field=models.BooleanField(default=False),
preserve_default=True,
),
],
)
Example: Adding a boolean field
Let’s assume you’d like to add a boolean field to a large table that is false
by default. By testing the migration on your staging database you established
that using BooleanField(default=False) will be too slow so picking a
NullBooleanField(default=False) seems like a natural
choice.
Running the migration with django-admin sqlmigrate reveals what Django is doing here:
BEGIN;
ALTER TABLE users ADD COLUMN blocked BOOLEAN DEFAULT false NULL;
ALTER TABLE users ALTER COLUMN blocked DROP DEFAULT;
COMMIT;
Try running these queries in psql with \timing and you’ll see that the ADD COLUMN will do a table rewrite to write the default value into the existing
rows.
What you can do is setting up multiple migrations:
Add the field as nullable without a default
migrations.AddField(
model_name='user',
name='blocked',
field=models.NullBooleanField(),
preserve_default=True,
)
This requires an exclusive lock for adding a column but doesn’t perform a table rewrite.
Add the default to the database schema
RunSQL(
'ALTER TABLE users ALTER COLUMN blocked SET DEFAULT false',
'ALTER TABLE users ALTER COLUMN blocked DROP DEFAULT',
state_operations=[
migrations.AlterField(
model_name='user',
name='blocked',
field=models.NullBooleanField(default=False),
preserve_default=True,
)
],
)
Adding a default to an existing column also doesn’t require an expensive table rewrite.
Update existing rows
Update December 2017: Support for non-atomic migrations was added to Django 1.10. The following hacks are not necessary anymore.
Updating data in batches as part of your data migration is tricky because you will have to break out of the database transaction that is already started by the migration executor.
One could contain the admittedly messy transaction break out logic into a
decorator to be used with the RunPython operation:
def non_atomic_migration(func):
@wraps(func)
def wrapper(apps, schema_editor):
if schema_editor.connection.in_atomic_block:
schema_editor.atomic.__exit__(None, None, None)
return func(apps, schema_editor)
return wrapper
The actual data migration would then look like that:
BATCHSIZE = 1000
@non_atomic_migration
def initialize_data(apps, schema_editor):
User = apps.get_model("user", "User")
max_pk = User.objects.aggregate(Max('pk'))['pk__max']
if max_pk is not None:
for offset in range(0, max_pk+1, BATCHSIZE):
(User.objects
.filter(pk__gte=offset)
.filter(pk__lt=offset+BATCHSIZE)
.filter(blocked__isnull=True)
.update(blocked=False))
class Migration(migrations.Migration):
operations = [
migrations.RunPython(initialize_data, atomic=False),
]
Hopefully this will be addressed in future versions of Django so that it won’t be necessary to resort to this kind of hack.
Set the not null constraint on the field
migrations.AlterField(
model_name='user',
name='blocked',
field=models.BooleanField(default=False),
preserve_default=True,
)
This will perform a table scan before it sets the constraint on the database.
Remove a table or column
Removing a table or even a column is easy but has one slight twist compared to the other scenarios: You need to run the migration after the new code is deployed to all of your servers.
Watch out if the column you’re removing has a not-null constraint but no default value defined in the schema. INSERT operations from your new code will fail until the column removal migration is applied. In this case, you will have to drop the not null constraint or add a default in an intermediate migration.
If you perform migrations as part of your deployment process as outlined above, you’ll have to split the deployment in two phases. In the first phase, the column is removed from the model and not-null constraints are dropped if necessary. Phase two only contains the column removal operation.
Transform and move data
So far we’ve only covered adding and removing features. It gets more interesting and challenging when the existing data model is changed. Let’s take the data migration example from the Django documentation, where separate first and last name fields are joined into one name field.
Let’s assume you just apply the migration while your application is running. The schema migration will add the new name column and the data migration will initialize the data for all existing users. During the time the migrations are running, the old code that reads and writes the old data is still active (let’s call that V1). Afterwards you’d deploy the code that reads and writes the new data only (V2).
There are a couple of problems:
- Users inserted by V1 after running the data migration don’t have a name set
- Users changed by V1 after running the data migration have the wrong name set
One could re-run the data migration after V2 is deployed to all servers. However, unless you keep track of which record is modified by which version, you’d lose updates from V2 because you’d rewrite the old data.
Another option is to have an intermediate version of your web application which writes both the old and the new representation:
def set_name(person, name):
person.name = name
person.first_name, person.last_name = name.rsplit(' ', 1)
person.save()
If you ignore the inaccuracy of the name splitting implementation, this would solve most problems. Just make sure to run the data migration for the untouched records after the deployment of the intermediate version. However, this gets quite cumbersome if you update this record in more than one place.
In order to contain the logic to one single spot you could move that logic into a pre-save signal of the person model. Remember that the signal won’t fire when updating multiple objects at once.
If the latter is a problem in your context, there is one more possibility that works surprisingly well for this use-case: Database triggers.
CREATE OR REPLACE FUNCTION update_person_name() RETURNS trigger AS $func$
BEGIN
IF NEW.first_name IS NULL THEN
NEW.first_name = split_part(NEW.name, ' ', 1);
NEW.last_name = split_part(NEW.name, ' ', 2);
END IF;
RETURN NEW;
END;
$func$ LANGUAGE plpgsql;
CREATE TRIGGER on_person_update
BEFORE INSERT OR UPDATE ON person
FOR EACH ROW
EXECUTE PROCEDURE update_person_name();
The downsides of triggers are that those are hard to update, have limited capabilities and are mostly invisible. However, when rolling out more involved updates I found them to be very robust compared to the other approaches. Just remember to remove triggers after they served their purpose.
Summary
Apart from not requiring a downtime, there are various upsides of doing on-line migrations:
- Allows to perform rolling deployments
- Easier rollback
There are a couple of downsides:
- Increased complexity - there are more states the whole system can be in
- Intermediate states are hard to test
If you know what you’re doing or if you work for a company that puts too many nines into their SLAs, you might start carrying out all database migrations on a live system. For more involved database changes you’ll need more complicated migration rules, there will be more possible states your complete system can be in causing it to fail in more interesting and unexpected ways. At some complexity level, attempting zero-downtime migrations turns into what some people would call “mental masturbation” - especially if the development cost exceeds the total cost of just having a downtime.
However, many smaller schema changes can be safely carried out on a live site when keeping a few important things in mind:
- Add columns as nullable for bigger tables
- When adding NOT NULL columns, add a default to the database manually
- Keep migrations small
- Use django-admin sqlmigrate to understand what happens at the DB level
- Test and time your migrations on your staging database
- Temporarily shut down batch processing jobs which operate on tables to be changed
- Update rows of large tables in smaller transactional batches
Django wishlist
There are improvements that could be made in Django, which would simplify some of the migration scenarios. Here is my wishlist:
- Make it possible to mark migrations as non-atomic (added in Django 1.10)
- Allow to preserve defaults in the database (where possible)
- Allow flagging post-deployment migrations and allow to exempt those while migrating
Final notes
I hope this post was helpful. If you spot any errors or have any other remarks I’d appreciate if you’d raise an issue on GitHub or reach out via Twitter.